Pipe assemblies define what work should be done against a tuple stream, where during runtime tuple streams are read from Tap sources and are written to Tap sinks. Pipe assemblies may have multiple sources and multiple sinks and they can define splits, merges, and joins to manipulate how the tuple streams interact.

There are only five Pipe types: Pipe, Each, GroupBy, CoGroup, Every, and SubAssembly.
- Pipe
-
The
cascading.pipe.Pipeclass is used to name branches of pipe assemblies. These names are used during planning to bind Taps as either sources or sinks (or as traps, an advanced topic). It is also the base class for all other pipes described below. - Each
-
The
cascading.pipe.Eachpipe applies aFunctionorFilterOperation to each Tuple that passes through it. - GroupBy
-
cascading.pipe.GroupBymanages one input Tuple stream and does exactly as it sounds, that is, groups the stream on selected fields in the tuple stream.GroupByalso allows for "merging" of two or more tuple stream that share the same field names. - CoGroup
-
cascading.pipe.CoGroupallows for "joins" on a common set of values, just like a SQL join. The output tuple stream ofCoGroupis the joined input tuple streams, where a join can be an Inner, Outer, Left, or Right join. - Every
-
The
cascading.pipe.Everypipe applies anAggregator(like count, or sum) orBuffer(a sliding window) Operation to every group of Tuples that pass through it. - SubAssembly
-
The
cascading.pipe.SubAssemblypipe allows for nesting reusable pipe assemblies into a Pipe class for inclusion in a larger pipe assembly. See the section onSubAssemblies.
Pipe assemblies are created by chaining
cascading.pipe.Pipe classes and
Pipe subclasses together. Chaining is
accomplished by passing previous Pipe instances
to the constructor of the next Pipe
instance.
Example 3.1. Chaining Pipes
// the "left hand side" assembly head Pipe lhs = new Pipe( "lhs" ); lhs = new Each( lhs, new SomeFunction() ); lhs = new Each( lhs, new SomeFilter() ); // the "right hand side" assembly head Pipe rhs = new Pipe( "rhs" ); rhs = new Each( rhs, new SomeFunction() ); // joins the lhs and rhs Pipe join = new CoGroup( lhs, rhs ); join = new Every( join, new SomeAggregator() ); join = new GroupBy( join ); join = new Every( join, new SomeAggregator() ); // the tail of the assembly join = new Each( join, new SomeFunction() );
The above example, if visualized, would look like the diagram below.
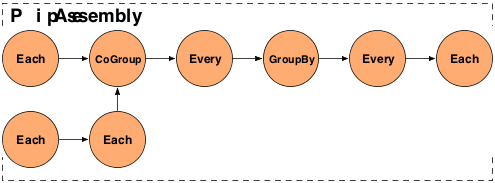
Here are some common stream patterns.
- Split
-
A split takes a single stream and sends it down one or more paths. This is simply achieved by passing a given
Pipeinstance to two or more subsequentPipeinstances. Note you can use thePipeclass and name the branch (branch names are useful for bindingFailure Traps), or with aEachclass. - Merge
-
A merge is where two or more streams with the exact same Fields (and types) are treated as a single stream. This is achieved by passing two or more
Pipeinstances to aGroupByPipeinstance. - Join
-
A join is where two or more streams are connected by one or more common values. See the previous diagram for an example.
Besides defining the paths tuple streams take through splits, merges, grouping, and joining, pipe assemblies also transform and/or filter the stored values in each Tuple. This is accomplished by applying an Operation to each Tuple or group of Tuples as the tuple stream passes through the pipe assembly. To do that, the values in the Tuple typically are given field names, in the same fashion columns are named in a database so that they may be referenced or selected.
- Operation
-
Operations (
cascading.operation.Operation) accept an input argument Tuple, and output zero or more result Tuples. There are a few sub-types of operations defined below. Cascading has a number of generic Operations that can be reused, or developers can create their own custom Operations. - Tuple
-
In Cascading, we call each record of data a Tuple (
cascading.tuple.Tuple), and a series of Tuples are a tuple stream. Think of a Tuple as an Array of values where each value can be anyjava.lang.ObjectJava type (orbyte[]array). See the section on Custom Types for supporting non-primitive values. - Fields
-
Fields (
cascading.tuple.Fields) either declare the field names in a Tuple. Or reference values in a Tuple as a selector. Fields can either be string names ("first_name"), integer positions (-1for the last value), or a substitution (Fields.ALLto select all values in the Tuple, like an asterisk (*) in SQL, seeField Algebra).
The Each and Every
pipe types are the only pipes that can be used to apply Operations to
the tuple stream.
The Each pipe applies an Operation to
"each" Tuple as it passes through the pipe assembly. The
Every pipe applies an Operation to "every"
group of Tuples as they pass through the pipe assembly, on the tail
end of a GroupBy or
CoGroup pipe.
new Each( previousPipe, argumentSelector, operation, outputSelector )
new Every( previousPipe, argumentSelector, operation, outputSelector )
Both the Each and
Every pipe take a Pipe instance, an argument
selector, Operation instance, and a output selector on the
constructor. Where each selector is a Fields instance.
The Each pipe may only apply
Functions and Filters to
the tuple stream as these operations may only operate on one Tuple at
a time.
The Every pipe may only apply
Aggregators and Buffers
to the tuple stream as these operations may only operate on groups of
tuples, one grouping at a time.
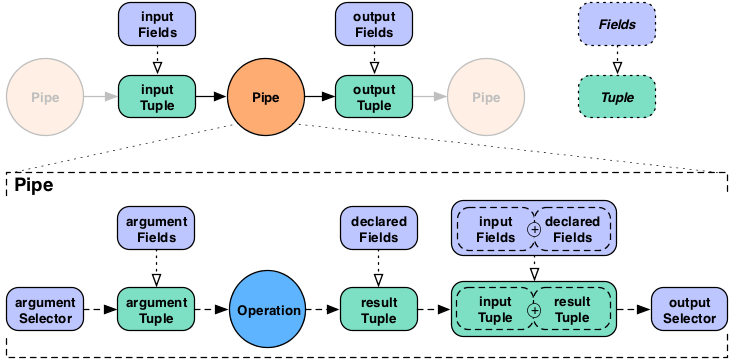
The "argument selector" selects values from the input Tuple to be passed to the Operation as argument values. Most Operations declare result fields, "declared fields" in the diagram. The "output selector" selects the output Tuple from an "appended" version of the input Tuple and the Operation result Tuple. This new output Tuple becomes the input Tuple to the next pipe in the pipe assembly.
Note that if a Function or
Aggregator emits more than one Tuple, this
process will be repeated for each result Tuple against the original
input Tuple, depending on the output selector, input Tuple values
could be duplicated across each output Tuple.

If the argument selector is not given, the whole input Tuple
(Fields.ALL) is passed to the Operation as argument
values. If the result selector is not given on an
Each pipe, the Operation results are returned
by default (Fields.RESULTS), replacing the input Tuple
values in the tuple stream. This really only applies to
Functions, as Filters
either discard the input Tuple, or return the input Tuple intact.
There is no opportunity to provide an output selector.
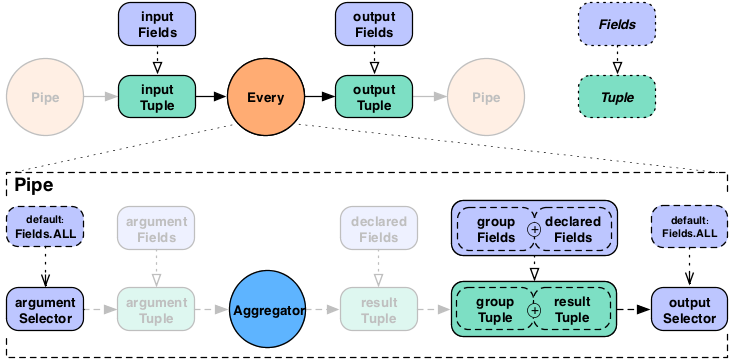
For the Every pipe, the Aggregator
results are appended to the input Tuple (Fields.ALL) by
default.
It is important to note that the Every
pipe associates Aggregator results with the current group Tuple. For
example, if you are grouping on the field "department" and counting
the number of "names" grouped by that department, the output Fields
would be ["department","num_employees"]. This is true for both
Aggregator, seen above, and
Buffer.
If you were also adding up the salaries associated with each
"name" in each "department", the output Fields would be
["department","num_employees","total_salaries"]. This is only true for
chains of Aggregator Operations, you may not
chain Buffer Operations.
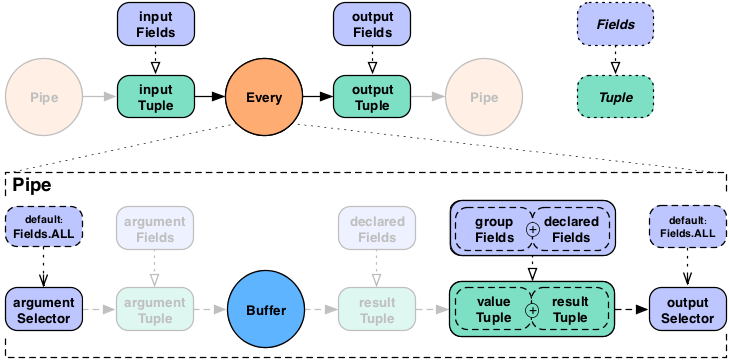
For the Every pipe when used with a
Buffer the behavior is slightly different.
Instead of associating the Buffer results with the current grouing
Tuple, they are associated with the current values Tuple, just like an
Each pipe does with a
Function. This might be slightly more
confusing, but provides much more flexibility.
The GroupBy and
CoGroup pipes serve two roles. First, they emit
sorted grouped tuple streams allowing for Operations to be applied to
sets of related Tuple instances. Where "sorted" means the tuple groups
are emitted from the GroupBy and
CoGroup pipes in sort order of the field values
the groups were grouped on.
Second, they allow for two streams to be either merged or joined. Where merging allows for two or more tuple streams originating from different sources to be treated as a single stream. And joining allows two or more streams to be "joined" (in the SQL sense) on a common key or set of Tuple values in a Tuple.
It is not required that an Every follow
either GroupBy or CoGroup, an
Each may follow immediately after. But an
Every many not follow an
Each.
It is important to note, for both GroupBy
andCoGroup, the values being grouped on must be
the same type. If your application attempts to
GroupBy on the field "size", but the value
alternates between a String and a
Long, Hadoop will fail internally attempting to
apply a Java Comparator to them. This also
holds true for the secondary sorting sort-by fields in
GroupBy.
GroupBy accepts one or more tuple
streams. If two or more, they must all have the same field names (this
is also called a merge, see below).
Example 3.2. Grouping a Tuple Stream
Pipe groupBy = new GroupBy( assembly, new Fields( "group1", "group2" ) );
The example above simply creates a new tuple stream where Tuples
with the same values in "group1" and "group2" can be processed as a
set by an Aggregator or
Buffer Operation. The resulting stream of
tuples will be sorted by the values in "group1" and "group2".
Example 3.3. Merging a Tuple Stream
Pipe[] pipes = Pipe.pipes( lhs, rhs ); Pipe merge = new GroupBy( pipes, new Fields( "group1", "group2" ) );
This example merges two streams ("lhs" and "rhs") into one tuple stream and groups the resulting stream on the fields "group1" and "group2", in the same fashion as the previous example.
CoGroup accepts two or more tuple streams and does not require any common field names. The grouping fields must be provided for each tuple stream.
Example 3.4. Joining a Tuple Stream
Fields lhsFields = new Fields( "fieldA", "fieldB" ); Fields rhsFields = new Fields( "fieldC", "fieldD" ); Pipe join = new CoGroup( lhs, lhsFields, rhs, rhsFields, new InnerJoin() );
This example joins two streams ("lhs" and "rhs") on common values. Note that common field names are not required here. Actually, if there were any common field names, the Cascading planner would throw an error as duplicate field names are not allowed.
This is significant because of the nature of joining streams.
The first stage of joining has to do with identifying field names that represent the grouping key for a given stream. The second stage is emitting a new Tuple with the joined values, this includes the grouping values, and the other values.
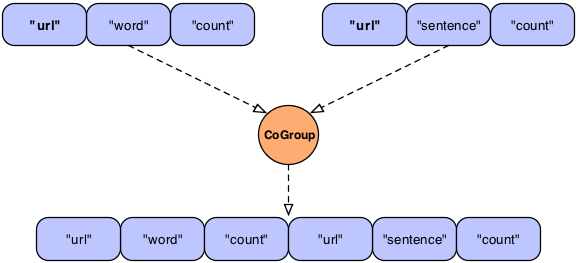
In the above example, we see what "logically" happens during a
join. Here we join two streams on the "url" field which happens to be
common to both streams. The result is simply two Tuple instances with
the same "url" appended together into a new Tuple. In practice this
would fail since the result Tuple has duplicate field names. The
CoGroup pipe has the
declaredFields argument allowing the developer
to declare new unique field names for the resulting tuple.
Example 3.5. Joining a Tuple Stream with Duplicate Fields
Fields common = new Fields( "url" ); Fields declared = new Fields( "url1", "word", "wd_count", "url2", "sentence", "snt_count" ); Pipe join = new CoGroup( lhs, common, rhs, common, declared, new InnerJoin() );
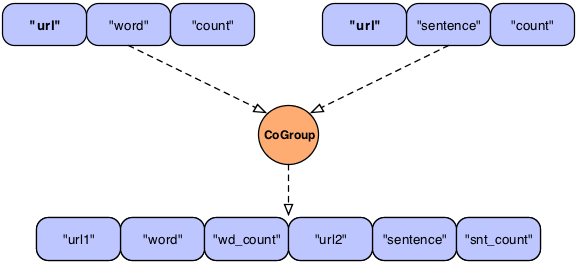
Here we see an example of what the developer could have named the fields so the planner would not fail.
It is important to note that Cascading could just magically create a new Tuple by removing the duplicate grouping fields names so the user isn't left renaming them. In the above example, the duplicate "url" columns could be collapsed into one, as they are the same value. This is not done because field names are a user convenience, the primary mechanism to manipulate Tuples is through positions, not field names. So the result of every Pipe (Each, Every, CoGroup, GroupBy) needs to be deterministic. This gives Cascading a big performance boost, provides a means for sub-assemblies to be built without coupling to any "domain level" concepts (like "first_name", or "url), and allows for higher level abstractions to be built on-top of Cascading simply.
In the example above, we explicitly set a Joiner class to join
our data. The reason CoGroup is named "CoGroup"
and not "Join" is because joining data is done after all the parallel
streams are co-grouped by their common keys. The details are not
terribly important, but note that a "bag" of data for every input
tuple stream must be created before an join operation can be
performed. Each bag consists of all the Tuple instances associated
with a given grouping Tuple.

Above we see two bags, one for each tuple stream ("lhs" and
"rhs"). Each Tuple in bag is independent but all Tuples in both bags
have the same "url" value since we are grouping on "url", from the
previous example. A Joiner will match up every Tuple on the "lhs" with
a Tuple on the "rhs". An InnerJoin is the most common. This is where
each Tuple on the "lhs" is matched with every Tuple on the "rhs". This
is the default behaviour one would see in SQL when doing a join. If
one of the bags was empty, no Tuples would be joined. An OuterJoin
allows for either bag to be empty, and if that is the case, a Tuple
full of null values would be substituted.
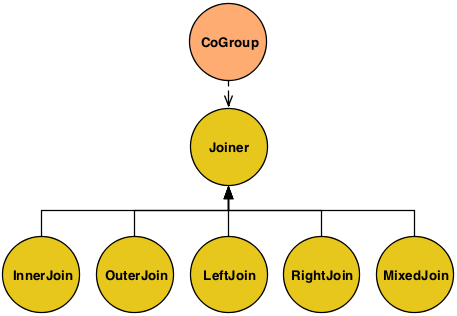
Above we see all supported Joiner types.
LHS = [0,a] [1,b] [2,c]
RHS = [0,A] [2,C] [3,D] Using the above simple data
sets, we will define each join type where the values are joined on the
first position, a numeric value. Note when Cascading joins Tuples, the
resulting Tuple will contain all the incoming values. The duplicate
common key(s) is not discarded if given. And on outer joins, where
there is no equivalent key in the alternate stream, null
values are used as placeholders. - InnerJoin
-
An Inner join will only return a joined Tuple if neither bag has is empty.
[0,a,0,A] [2,c,2,C]
- OuterJoin
-
An Outer join will join if either the left or right bag is empty.
[0,a,0,A] [1,b,null,null] [2,c,2,C] [null,null,3,D]
- LeftJoin
-
A Left join can also be stated as a Left Inner and Right Outer join, where it is fine if the right bag is empty.
[0,a,0,A] [1,b,null,null] [2,c,2,C]
- RightJoin
-
A Right join can also be stated as a Left Outer and Right Inner join, where it is fine if the left bag is empty.
[0,a,0,A] [2,c,2,C] [null,null,3,D]
- MixedJoin
-
A Mixed join is where 3 or more tuple streams are joined, and each pair must be joined differently. See the
cascading.pipe.cogroup.MixedJoinclass for more details. - Custom
-
A custom join is where the developer subclasses the
cascading.pipe.cogroup.Joinerclass.
By virtue of the Reduce method, in the MapReduce model
encapsulated by GroupBy and
CoGroup, all groups of Tuples will be locally
sorted by their grouping values. That is, both the
Aggregator and Buffer
Operations will receive groups in their natural sort order. But the
values associated within those groups are not sorted.
That is, if we sort on 'lastname' with the tuples [john,
doe] and[jane, doe], the 'firstname' values will
arrive in an arbitrary order to the
Aggregator.aggregate() method.
In the below example we provide sorting fields to the
GroupBy instance. Now value1 and
value2 will arrive in their natural sort order (assuming
value1 and value2 are
java.lang.Comparable).
Example 3.6. Secondary Sorting
Fields groupFields = new Fields( "group1", "group2" ); Fields sortFields = new Fields( "value1", "value2" ); Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );
If we didn't care about the order ofvalue2, would
could have left it out of the sortFields
Fields constructor.
In this example, we reverse the order of value1
while keeping the natural order ofvalue2.
Example 3.7. Reversing Secondary Sort Order
Fields groupFields = new Fields( "group1", "group2" ); Fields sortFields = new Fields( "value1", "value2" ); sortFields.setComparator( "value1", Collections.reverseOrder() ); Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );
Whenever there is an implied sort, during grouping or secondary
sorting, a custom java.util.Comparator can be
supplied to the grouping Fields or secondary
sort Fields to influence the sorting through
the Fields.setComparator() call.
Creating a custom Comparator also allows
for non- Comparable classes to be sorted and/or
grouped on.
Here is a more practical example were we group by the 'day of the year', but want to reverse the order of the Tuples within that grouping by 'time of day'.
Example 3.8. Reverse Order by Time
Fields groupFields = new Fields( "year", "month", "day" ); Fields sortFields = new Fields( "hour", "minute", "second" ); sortFields.setComparators( Collections.reverseOrder(), // hour Collections.reverseOrder(), // minute Collections.reverseOrder() ); // second Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );