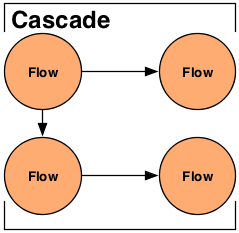
A Cascade allows multiple Flow instances to be executed as a single logical unit. If there are dependencies between the Flows, they will be executed in the correct order. Further, Cascades act like ant build or Unix "make" files. When run, a Cascade will only execute Flows that have stale sinks (output data that is older than the input data), by default.
Example 3.14. Creating a new Cascade
CascadeConnector connector = new CascadeConnector(); Cascade cascade = connector.connect( flowFirst, flowSecond, flowThird );
When passing Flows to the CascadeConnector, order is not important. The CascadeConnector will automatically determine what the dependencies are between the given Flows and create a scheduler that will start each flow as its data sources become available. If two or more Flow instances have no dependencies, they will be submitted together so they can execute in parallel.
For more information, see the section onTopological Scheduling.
If an instance of
cascading.flow.FlowSkipStrategy is given to an
Cascade instance via the
Cascade#setFlowSkipStrategy() method, it will be
consulted for every Flow instance managed by the Cascade, all skip
strategies on the Flow instances will be ignored. For more information
on skip strategies, seeSkipping Flows.