The MapReduce Job Planner is an internal feature of Cascading.
When a collection of functions, splits, and joins are all tied up together into a 'pipe assembly', the FlowConnector object is used to create a new Flow instance against input and output data paths. This Flow is a single Cascading job.
Internally the FlowConnector employs an intelligent planner to convert the pipe assembly to a graph of dependent MapReduce jobs that can be executed on a Hadoop cluster.
All this happens under the scenes. As is the scheduling of the individual MapReduce jobs, and the clean up of intermediate data sets that bind the jobs together.
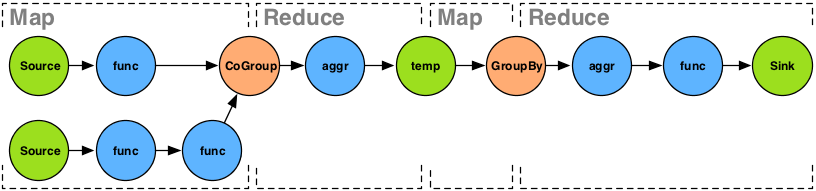
Above we can see how a reasonably normal Flow would be partitioned into MapReduce jobs. Every job is delimited by a temporary file that is the sink from the first job, and then the source to the next job.
To see how your Flows are partitioned, call the
Flow#writeDOT() method. This will write a DOT file
out to the path specified, and can be imported into a graphics package
like OmniGraffle or Graphviz.