The Hadoop MapReduce Job Planner is an internal feature of Cascading.
When a collection of functions, splits, and joins are all tied up together into a "pipe assembly", the FlowConnector object is used to create a new Flow instance against input and output data paths. This Flow is a single Cascading job.
Internally, the FlowConnector employs an intelligent planner to convert the pipe assembly to a graph of dependent MapReduce jobs that can be executed on a Hadoop cluster.
All this happens behind the scenes - as does the scheduling of the individual MapReduce jobs, and the cleanup of intermediate data sets that bind the jobs together.
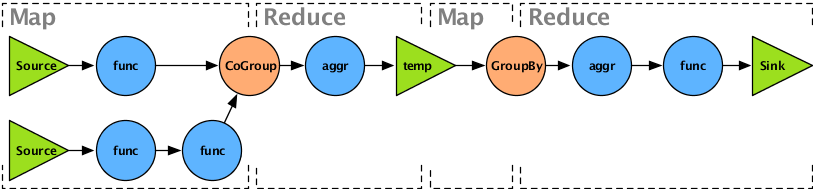
The diagram above shows how a typical Flow is partitioned into MapReduce jobs. Every job is delimited by a temporary file that serves as the sink from the first job and the source for the next.
To create a visualization of how your Flows are partitioned, call
the Flow#writeDOT() method. This writes a DOT file
out to the path specified, which can be viewed in a graphics package
like OmniGraffle or Graphviz.