Pipe assemblies define what work should be done against tuple streams, which are read from tap sources and written to tap sinks. The work performed on the data stream may include actions such as filtering, transforming, organizing, and calculating. Pipe assemblies may use multiple sources and multiple sinks, and may define splits, merges, and joins to manipulate the tuple streams.
Pipe assemblies are created by chaining
cascading.pipe.Pipe classes and subclasses
together. Chaining is accomplished by passing the previous
Pipe instances to the constructor of the next
Pipe instance.
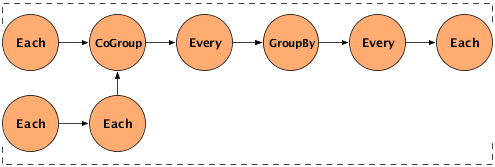
The following example demonstrates this type of chaining. It creates two pipes - a "left-hand side" (lhs) and a "right-hand side" (rhs) - and performs some processing on them both, using the Each pipe. Then it joins the two pipes into one, using the CoGroup pipe, and performs several operations on the joined pipe using Every and GroupBy. The specific operations performed are not important in the example; the point is to show the general flow of the data streams. The diagram after the example gives a visual representation of the workflow.
Example 3.1. Chaining Pipes
// the "left hand side" assembly head
Pipe lhs = new Pipe( "lhs" );
lhs = new Each( lhs, new SomeFunction() );
lhs = new Each( lhs, new SomeFilter() );
// the "right hand side" assembly head
Pipe rhs = new Pipe( "rhs" );
rhs = new Each( rhs, new SomeFunction() );
// joins the lhs and rhs
Pipe join = new CoGroup( lhs, rhs );
join = new Every( join, new SomeAggregator() );
join = new GroupBy( join );
join = new Every( join, new SomeAggregator() );
// the tail of the assembly
join = new Each( join, new SomeFunction() );
The following diagram is a visual representation of the example above.
As data moves through the pipe, streams may be separated or combined for various purposes. Here are the three basic patterns:
- Split
-
A split takes a single stream and sends it down multiple paths - that is, it feeds a single
Pipeinstance into two or more subsequent separatePipeinstances with unique branch names. - Merge
-
A merge combines two or more streams that have identical fields into a single stream. This is done by passing two or more
Pipeinstances to aMergeorGroupBypipe. - Join
-
A join combines data from two or more streams that have different fields, based on common field values (analogous to a SQL join.) This is done by passing two or more
Pipeinstances to aHashJoinorCoGrouppipe. The code sequence and diagram above give an example.
In addition to directing the tuple streams - using splits, merges, and joins - pipe assemblies can examine, filter, organize, and transform the tuple data as the streams move through the pipe assemblies. To facilitate this, the values in the tuple are typically given field names, just as database columns are given names, so that they may be referenced or selected. The following terminology is used:
- Operation
-
Operations (
cascading.operation.Operation) accept an input argument Tuple, and output zero or more result tuples. There are a few sub-types of operations defined below. Cascading has a number of generic Operations that can be used, or developers can create their own custom Operations. - Tuple
-
In Cascading, data is processed as a stream of Tuples (
cascading.tuple.Tuple), which are composed of fields, much like a database record or row. A Tuple is effectively an array of (field) values, where each value can be anyjava.lang.ObjectJava type (orbyte[]array). For information on supporting non-primitive types, see Custom Types. - Fields
-
Fields (
cascading.tuple.Fields) are used either to declare the field names for fields in a Tuple, or reference field values in a Tuple. They can either be strings (such as "firstname" or "birthdate"), integers (for the field position, starting at0for the first position, or starting at-1for the last position), or one of the predefined Fields sets (such asFields.ALL, which selects all values in the Tuple, like an asterisk in SQL). For more on Fields sets, see Field Algebra).