The code for the sample pipe assembly above, Chaining Pipes, consists almost entirely of a series of
Pipe constructors. This section describes the
various Pipe classes in detail. The base class
cascading.pipe.Pipe and its subclasses are shown
in the diagram below.
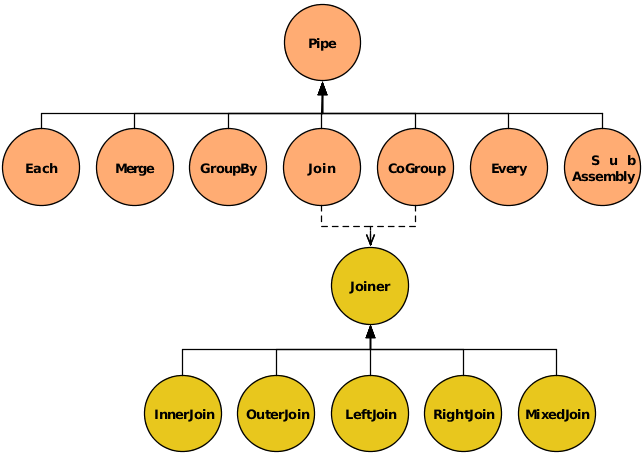
The Pipe class
is used to instantiate and name a pipe. Pipe names are
used by the planner to bind taps to the pipe as sources or sinks. (A
third option is to bind a tap to the pipe branch as a trap, discussed elsewhere as an advanced
topic.)
The SubAssembly
subclass is a special type of pipe. It is used to nest
re-usable pipe assemblies within a Pipe class
for inclusion in a larger pipe assembly. For more information on
this, see the section on SubAssemblies.
The other six types of pipes are used to perform operations on the tuple streams as they pass through the pipe assemblies. This may involve operating on the individual tuples (e.g., transform or filter), on groups of related tuples (e.g., count or subtotal), or on entire streams (e.g., split, combine, group, or sort). These six pipe types are briefly introduced here, then explored in detail further below.
Each-
These pipes perform operations based on the data contents of tuples - analyze, transform, or filter. The
Eachpipe operates on individual tuples in the stream, applying functions or filters such as conditionally replacing certain field values, removing tuples that have values outside a target range, etc.You can also use
Eachto split or branch a stream, simply by routing the output of anEachinto a different pipe or sink.Note that with
Each, as with other types of pipe, you can specify a list of fields to output, thereby removing unwanted fields from a stream. Merge-
Just as
Eachcan be used to split one stream into two,Mergecan be used to combine two or more streams into one, as long as they have the same fields.A
Mergeaccepts two or more streams that have identical fields, and emits a single stream of tuples (in arbitrary order) that contains all the tuples from all the specified input streams. Thus a Merge is just a mingling of all the tuples from the input streams, as if shuffling multiple card decks into one.Use
Mergewhen no grouping is required (i.e., no aggregator or buffer operations will be performed).Mergeis much faster thanGroupBy(see below) for merging.To combine streams that have different fields, based on one or more common values, use
CoGrouporHashJoin. GroupBy-
GroupBygroups the tuples of a stream based on common values in a specified field.If passed multiple streams as inputs, it performs a merge before the grouping. As with
Merge, aGroupByrequires that multiple input streams share the same field structure.The purpose of grouping is typically to prepare a stream for processing by the
Everypipe, which performs aggregator and buffer operations on the groups, such as counting, totalling, or averaging values within that group.It should be clear that "grouping" here essentially means sorting all the tuples into groups based on the value of a particular field. However, within a given group, the tuples are in arbitrary order unless you specify a secondary sort key. For most purposes, a secondary sort is not required and only increases the execution time.
Every-
The
Everypipe operates on a tuple stream that has been grouped (byGroupByorCoGroup) on the values of a particular field, such as timestamp or zipcode. It's used to apply aggregator or buffer operations such as counting, totaling, or averaging field values within each group. Thus theEveryclass is only for use on the output ofGroupByorCoGroup, and cannot be used with the output ofEach,Merge, orHashJoin.An
Everyinstance may follow anotherEveryinstance, soAggregatoroperations can be chained. This is not true forBufferoperations. CoGroup-
CoGroupperforms a join on two or more streams, similar to a SQL join, and groups the single resulting output stream on the value of a specified field. As with SQL, the join can be inner, outer, left, or right. Self-joins are permitted, as well as mixed joins (for three or more streams) and custom joins. Null fields in the input streams become corresponding null fields in the output stream.The resulting output stream contains fields from all the input streams. If the streams contain any field names in common, they must be renamed to avoid duplicate field names in the resulting tuples.
HashJoin-
HashJoinperforms a join on two or more streams, similar to a SQL join, and emits a single stream in arbitrary order. As with SQL, the join can be inner, outer, left, or right. Self-joins are permitted, as well as mixed joins (for three or more streams) and custom joins. Null fields in the input streams become corresponding null fields in the output stream.For applications that do not require grouping,
HashJoinprovides faster execution thanCoGroup, but only within certain prescribed cases. It is optimized for joining one or more small streams to no more than one large stream. Developers should thoroughly understand the limitations of this class, as described below, before attempting to use it.
The following table summarizes the different types of pipes.
Table 3.1. Comparison of pipe types
| Pipe type | Purpose | Input | Output |
Pipe | instantiate a pipe; create or name a branch | name | a (named) pipe |
SubAssembly | create nested subassemblies | ||
Each | apply a filter or function, or branch a stream | tuple stream (grouped or not) | a tuple stream, optionally filtered or transformed |
Merge | merge two or more streams with identical fields | two or more tuple streams | a tuple stream, unsorted |
GroupBy | sort/group on field values; optionally merge two or more streams with identical fields | two or more tuple streams with identical fields | a single tuple stream, grouped on key field(s) with optional secondary sort |
Every | apply aggregator or buffer operation | grouped tuple stream | a tuple stream plus new fields with operation results |
CoGroup | join 1 or more streams on matching field values | one or more tuple streams | a single tuple stream, joined on key field(s) |
HashJoin | join 1 or more streams on matching field values | one or more tuple streams | a tuple stream in arbitrary order |
The Each and Every
pipes perform operations on tuple data - for instance, perform a
search-and-replace on tuple contents, filter out some of the tuples
based on their contents, or count the number of tuples in a stream
that share a common field value.
Here is the syntax for these pipes:
new Each( previousPipe, argumentSelector, operation, outputSelector )
new Every( previousPipe, argumentSelector, operation, outputSelector )
Both types take four arguments:
-
a Pipe instance
-
an argument selector
-
an Operation instance
-
an output selector on the constructor (selectors here are Fields instances)
The key difference between Each and
Every is that the Each
operates on individual tuples, and Every
operates on groups of tuples emitted by GroupBy
or CoGroup. This affects the kind of operations
that these two pipes can perform, and the kind of output they produce
as a result.
The Each pipe applies operations that are
subclasses of Functions and
Filters (described in the Javadoc). For
example, using Each you can parse lines from a
logfile into their constituent fields, filter out all lines except the
HTTP GET requests, and replace the timestring fields with date
fields.
Similarly, since the Every pipe works on
tuple groups (the output of a GroupBy or
CoGroup pipe), it applies operations that are
subclasses of Aggregators and
Buffers. For example, you could use
GroupBy to group the output of the above
Each pipe by date, then use an
Every pipe to count the GET requests per date.
The pipe would then emit the operation results as the date and count
for each group.
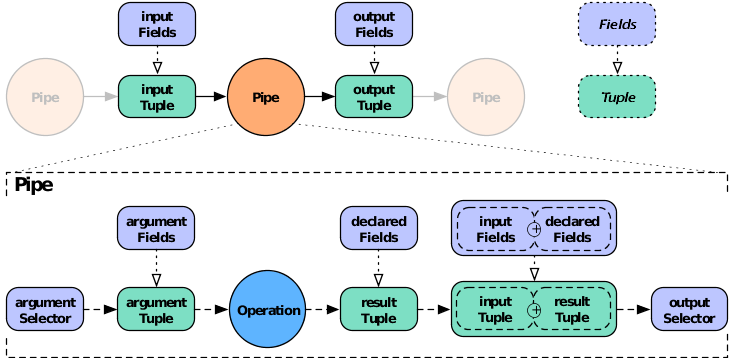
In the syntax shown at the start of this section, the argument selector specifies fields from the
input tuple to use as input values. If the argument selector is not
specified, the whole input tuple (Fields.ALL) is passed
to the operation as a set of argument values.
Most Operation subclasses declare result
fields (shown as "declared fields" in the diagram). The output selector specifies the fields of the
output Tuple from the fields of the input
Tuple and the operation result. This new output
Tuple becomes the input
Tuple to the next pipe in the pipe assembly. If
the output selector is Fields.ALL, the output is the input
Tuple plus the operation result, merged into a
single Tuple.
Note that it's possible for a Function or
Aggregator to return more than one output
Tuple per input Tuple. In
this case, the input tuple is duplicated as many times as necessary to
create the necessary output tuples. This is similar to the reiteration
of values that happens during a join. If a function is designed to
always emit three result tuples for every input tuple, each of the
three outgoing tuples will consist of the selected input tuple values
plus one of the three sets of function result values.
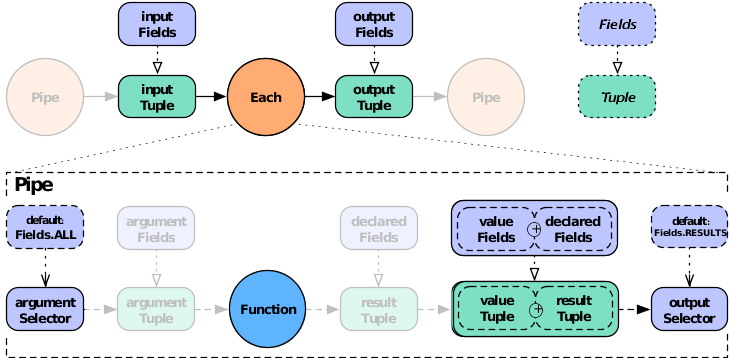
If the result selector is not specified for an
Each pipe performing a
Functions operation, the operation results are
returned by default (Fields.RESULTS), discarding the
input tuple values in the tuple stream. (This is not true of
Filters , which either discard the input tuple
or return it intact, and thus do not use an output selector.)
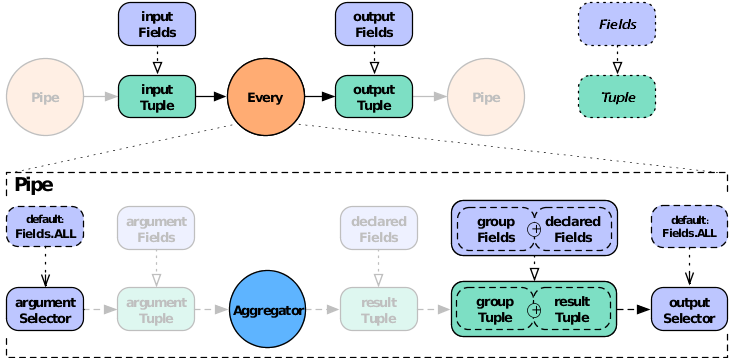
For the Every pipe, the Aggregator
results are appended to the input Tuple (Fields.ALL) by
default.
Note that the Every pipe associates
Aggregator results with the current group
Tuple (the unique keys currently being grouped
on). For example, if you are grouping on the field "department" and
counting the number of "names" grouped by that department, the
resulting output Fields will be ["department","num_employees"].
If you are also adding up the salaries associated with each "name" in each "department", the output Fields will be ["department","num_employees","total_salaries"].
This is only true for chains of
Aggregator Operations - you are not allowed to
chain Buffer operations, as explained
below.
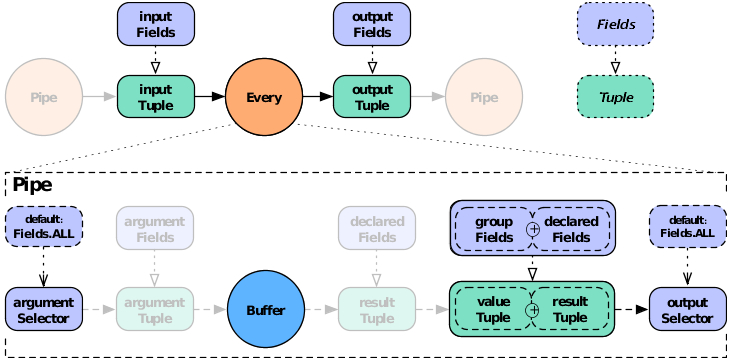
When the Every pipe is used with a
Buffer operation, instead of an
Aggregator, the behavior is different. Instead
of being associated with the current grouping tuple, the operation
results are associated with the current values tuple. This is
analogous to how an Each pipe works with a
Function. This approach may seem slightly
unintuitive, but provides much more flexibility. To put it another
way, the results of the buffer operation are not appended to the
current keys being grouped on. It is up to the buffer to emit them if
they are relevant. It is also possible for a Buffer to emit more than
one result Tuple per unique grouping. That is, a Buffer may or may not
emulate an Aggregator, where an Aggregator is just a special optimized
case of a Buffer.
For more information on how operations process fields, see Operations and Field-processing .
The Merge pipe is very simple. It accepts
two or more streams that have the same fields, and emits a single
stream containing all the tuples from all the input streams. Thus a
merge is just a mingling of all the tuples from the input streams, as
if shuffling multiple card decks into one. Note that the output of
Merge is in arbitrary order.
The example above simply combines all the tuples from two existing streams ("lhs" and "rhs") into a new tuple stream ("merge").
GroupBy groups the tuples of a stream
based on common values in a specified field. If passed multiple
streams as inputs, it performs a merge before the grouping. As with
Merge, a GroupBy
requires that multiple input streams share the same field
structure.
The output of GroupBy is suitable for the
Every pipe, which performs
Aggregator and Buffer
operations, such as counting, totalling, or averaging groups of tuples
that have a common value (e.g., the same date). By default,
GroupBy performs no secondary sort, so within
each group the tuples are in arbitrary order. For instance, when
grouping on "lastname", the tuples [doe, john] and
[doe, jane] end up in the same group, but in arbitrary
sequence.
If multi-level sorting is desired, the names of the sort
fields on must be specified to the GroupBy
instance, as seen below. In this example, value1 and
value2 will arrive in their natural sort order
(assuming they are
java.lang.Comparable).
Example 3.3. Secondary Sorting
Fields groupFields = new Fields( "group1", "group2" );
Fields sortFields = new Fields( "value1", "value2" );
Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );
If we don't care about the order of value2, we can
leave it out of the sortFields
Fields constructor.
In the next example, we reverse the order of
value1 while keeping the natural order of
value2.
Example 3.4. Reversing Secondary Sort Order
Fields groupFields = new Fields( "group1", "group2" );
Fields sortFields = new Fields( "value1", "value2" );
sortFields.setComparator( "value1", Collections.reverseOrder() );
Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );
Whenever there is an implied sort during grouping or secondary
sorting, a custom java.util.Comparator can
optionally be supplied to the grouping Fields
or secondary sort Fields. This allows the
developer to use the Fields.setComparator() call to
control the sort.
To sort or group on non-Java-comparable classes, consider
creating a custom Comparator.
Below is a more practical example, where we group by the "day of the year", but want to reverse the order of the tuples within that grouping by "time of day".
Example 3.5. Reverse Order by Time
Fields groupFields = new Fields( "year", "month", "day" );
Fields sortFields = new Fields( "hour", "minute", "second" );
sortFields.setComparators(
Collections.reverseOrder(), // hour
Collections.reverseOrder(), // minute
Collections.reverseOrder() ); // second
Pipe groupBy = new GroupBy( assembly, groupFields, sortFields );
The CoGroup pipe is similar to
GroupBy, but instead of a merge, performs a
join. That is, CoGroup accepts two or more
input streams and groups them on one or more specified keys, and
performs a join operation on equal key values, similar to a SQL
join.
The output stream contains all the fields from all the input streams.
As with SQL, the join can be inner, outer, left, or right. Self-joins are permitted, as well as mixed joins (for three or more streams) and custom joins. Null fields in the input streams become corresponding null fields in the output stream.
Since the output is grouped, it is suitable for the
Every pipe, which performs
Aggregator and Buffer
operations - such as counting, totalling, or averaging groups of
tuples that have a common value (e.g., the same date).
The output stream is sorted by the natural order of the grouping
fields. To control this order, at least the first
groupingFields value given should be an
instance of Fields containing
Comparator instances for the appropriate
fields. This allows fine-grained control of the sort grouping
order.
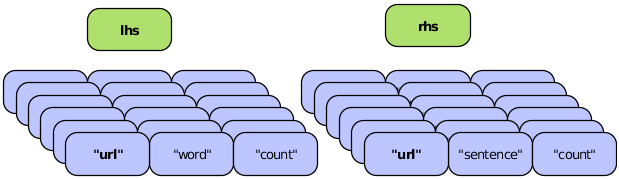
In a join operation, all the field names used in any of the input tuples must be unique; duplicate field names are not allowed. If the names overlap there is a collision, as shown in the following diagram.
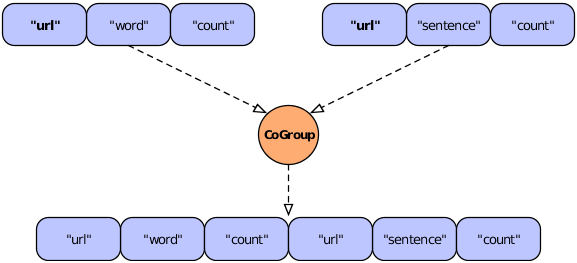
In this figure, two streams are to be joined on the "url"
field, resulting in a new Tuple that contains fields from the two
input tuples. However, the resulting tuple would include two fields
with the same name ("url"), which is unworkable. To handle the
conflict, developers can use the
declaredFields argument (described in the
Javadoc) to declare unique field names for the output tuple, as in
the following example.
Example 3.6. Joining Two Tuple Streams with Duplicate Field Names
Fields common = new Fields( "url" );
Fields declared = new Fields(
"url1", "word", "wd_count", "url2", "sentence", "snt_count"
);
Pipe join =
new CoGroup( lhs, common, rhs, common, declared, new InnerJoin() );
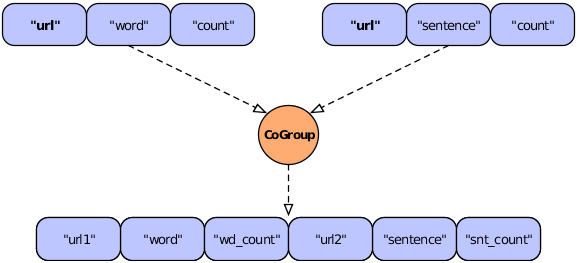
This revised figure demonstrates the use of declared field names to prevent a planning failure.
It might seem preferable for Cascading to automatically
recognize the duplication and simply merge the identically-named
fields, saving effort for the developer. However, consider the case
of an outer type join in which one field (or set of fields used for
the join) for a given join side happens to be null.
Discarding one of the duplicate fields would lose this
information.
Further, the internal implementation relies on field position,
not field names, when reading tuples; the field names are a device
for the developer. This approach allows the behavior of the
CoGroup to be deterministic and
predictable.
In the example above, we explicitly specified a Joiner class (InnerJoin) to perform a join on our data. There are five Joiner subclasses, as shown in this diagram.
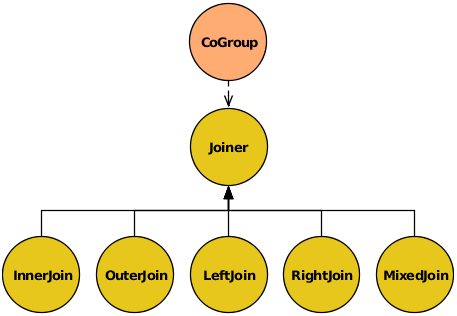
In CoGroup, the join is performed after
all the input streams are first co-grouped by their common keys.
Cascading must create a "bag" of data for every grouping in the
input streams, consisting of all the Tuple
instances associated with that grouping.
It's already been mentioned that joins in Cascading are
analogous to joins in SQL. The most commonly-used type of join is
the inner join, the default in CoGroup. An
inner join tries to match each
Tuple on the "lhs" with every
Tuple on the "rhs", based on matching field values. With an inner
join, if either side has no tuples for a given value, no tuples are
joined. An outer join, conversely, allows for either side to be
empty and simply substitutes a Tuple
containing null values for the non-existent
tuple.
This sample data is used in the discussion below to explain and compare the different types of join:
LHS = [0,a] [1,b] [2,c] RHS = [0,A] [2,C] [3,D]
In each join type
below, the values are joined on the first tuple position (the join
key), a numeric value. Note that, when Cascading joins tuples, the
resulting Tuple contains all the incoming
values from in incoming tuple streams, and does not discard the
duplicate key fields. As mentioned above, on outer joins where there
is no equivalent key in the alternate stream, null
values are used.
For example using the data above, the result Tuple of an
"inner" join with join key value of 2 would be
[2,c,2,C]. The result Tuple of an "outer" join with
join key value of 1 would be
[1,b,null,null].
- InnerJoin
-
An inner join only returns a joined
Tupleif neither bag for the join key is empty.[0,a,0,A] [2,c,2,C]
- OuterJoin
-
An outer join performs a join if one bag (left or right) for the join key is empty, or if neither bag is empty.
[0,a,0,A] [1,b,null,null] [2,c,2,C] [null,null,3,D]
- LeftJoin
-
A left join can also be stated as a left inner and right outer join, where it is acceptable for the right bag to be empty (but not the left).
[0,a,0,A] [1,b,null,null] [2,c,2,C]
- RightJoin
-
A right join can also be stated as a left outer and right inner join, where it is acceptable for the left bag to be empty (but not the right).
[0,a,0,A] [2,c,2,C] [null,null,3,D]
- MixedJoin
-
A mixed join is where 3 or more tuple streams are joined, using a small Boolean array to specify each of the join types to use. For more information, see the
cascading.pipe.cogroup.MixedJoinclass in the Javadoc. - Custom
-
Developers can subclass the
cascading.pipe.cogroup.Joinerclass to create custom join operations.
CoGroup attempts to store the entire
current unique keys tuple "bag" from the right-hand stream in memory
for rapid joining to the left-hand stream. If the bag is very large,
it may exceed a configurable threshold and be spilled to disk,
reducing performance and potentially causing a memory error (if the
threshold value is too large). Thus it's usually best to put the
stream with the largest groupings on the left-hand side and, if
necessary, adjust the spill threshold as described in the
Javadoc.
HashJoin performs a join (similar to a
SQL join) on two or more streams, and emits a stream of tuples that
contain fields from all of the input streams. With a join, the tuples
in the different input streams do not typically contain the same set
of fields.
As with CoGroup, the fieldnames must all
be unique, including the names of the key fields, to avoid duplicate
field names in the emitted Tuple. If necessary,
use the declaredFields argument to specify
unique field names for the output.
An inner join is performed by default, but you can choose inner, outer, left, right, or mixed (three or more streams). Self-joins are permitted. Developers can also create custom Joiners if desired. For more information on types of joins, refer to the section called “The Joiner class” or the Javadoc.
Example 3.7. Joining Two Tuple Streams
Fields lhsFields = new Fields( "fieldA", "fieldB" );
Fields rhsFields = new Fields( "fieldC", "fieldD" );
Pipe join =
new HashJoin( lhs, lhsFields, rhs, rhsFields, new InnerJoin() );
The example above performs an inner join on two streams ("lhs"
and "rhs"), based on common values in two fields. The field names that
are specified in lhsFields and
rhsFields are among the field names previously
declared for the two input streams.
For joins that do not require grouping,
HashJoin provides faster execution than
CoGroup, but it operates within stricter
limitations. It is optimized for joining one or more small streams
to no more than one large stream.
Unlike CoGroup,
HashJoin attempts to keep the entire
right-hand stream in memory for rapid comparison (not just the
current grouping, as no grouping is performed for a
HashJoin). Thus a very large tuple stream in
the right-hand stream may exceed a configurable spill-to-disk
threshold, reducing performance and potentially causing a memory
error. For this reason, it's advisable to use the smaller stream on
the right-hand side. Additionally, it may be helpful to adjust the
spill threshold as described in the Javadoc.
Due to the potential difficulties of using
HashJoin (as compared to the slower but much
more reliable CoGroup), developers should
thoroughly understand this class before attempting to use it.
Frequently the HashJoin is fed a
filtered down stream of Tuples from what was originally a very large
file. To prevent the large file from being replicated throughout a
cluster, when running in Hadoop mode, use a
Checkpoint pipe at the point where the data
has been filtered down to its smallest before it is streamed into a
HashJoin. This will force the Tuple stream to
be persisted to disk and new FlowStep
(MapReduce job) to be created to read the smaller data size more
efficiently.
By default, the properties passed to a FlowConnector subclass become the defaults for every Flow instance created by that FlowConnector. In the past, if some of the Flow instances needed different properties, it was necessary to create additional FlowConnectors to set those properties. However, it is now possible to set properties at the Pipe scope and at the process FlowStep scope.
Setting properties at the Pipe scope lets you set a property that is only visible to a given Pipe instance (and its child Operation). This allows Operations such as custom Functions to be dynamically configured.
More importantly, setting properties at the process FlowStep scope allows you to set properties on a Pipe that are inherited by the underlying process during runtime. When running on the Apache Hadoop platform (i.e., when using the HadoopFlowConnector), a FlowStep is the current MapReduce job. Thus a Hadoop-specific property can be set on a Pipe, such as a CoGroup. During runtime, the FlowStep (MapReduce job) that the CoGroup executes in is configured with the given property - for example, a spill threshold, or the number of reducer tasks for Hadoop to deploy.
The following code samples demonstrates the basic form for both the Pipe scope and the process FlowStep scope.
Example 3.8. Pipe Scope
Pipe join =
new HashJoin( lhs, common, rhs, common, declared, new InnerJoin() );
SpillableProps props = SpillableProps.spillableProps()
.setCompressSpill( true )
.setMapSpillThreshold( 50 * 1000 );
props.setProperties( join.getConfigDef(), ConfigDef.Mode.REPLACE );
Example 3.9. Step Scope
Pipe join =
new HashJoin( lhs, common, rhs, common, declared, new InnerJoin() );
SpillableProps props = SpillableProps.spillableProps()
.setCompressSpill( true )
.setMapSpillThreshold( 50 * 1000 );
props.setProperties( join.getStepConfigDef(), ConfigDef.Mode.DEFAULT );